本文主要讲解如何开启 Hadoop 中的 Yarn 日志聚合功能,从而在 Web UI 上查看日志信息,便于调试。注意,本文方法的 Hadoop 环境是 Hadoop 2.7.7。
1. 问题描述
在浏览器中输入 http://master机器ip:8088/可以进入 Yarn 的 Web UI 界面,在该界面中可以查看所有历史执行的 MapReduce 程序。如果想要查看某个MapReduce程序的执行日志,可以点击该程序右侧的 History 按钮,如下图所示的红框按钮。
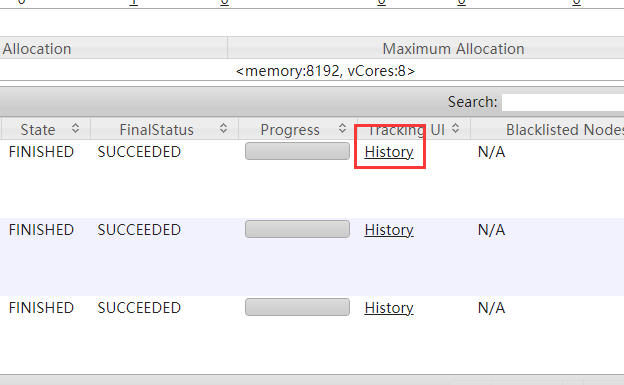
点击该按钮后,浏览器会跳转到一个新的地址,如:http://master:19888/jobhistory/job/job_1621165557010_0003。该地址无法正常显示的原因可能有两个:
- master 在当前主机中无法识别。如 Hadoop 环境在 Linux 中,然后在 Windows 环境中访问,此时 Windows 系统无法解析 master 的 IP
- 未配置 Yarn 的 日志服务
2. 解决办法
针对该问题,需要分别采取两种措施解决。
2.1 配置 Hosts 文件
如果是因为 Windows 系统无法识别主机名而不能访问,需要在 hosts 文件中添加 Linux 的主机名。进入 C:\Windows\System32\drivers\etc 路径,打开 hosts 文件,添加如下信息:
1
linux机器ip linux主机名
2.2 配置 Yarn
2.2.1 修改配置文件
在集群的 master 机器中进入 $HADOOP_HOME/etc/hadoop 路径,编辑 yarn-site.xml,添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
<!-- 开启 Hadoop 日志聚合功能,便于查看日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.27.132:19888/jobhistory/logs/</value>
</property>
然后,利用 scp 命令将 master 机器中的 yarn-site.xml 文件全部更新到集群的其它机器中。
2.2.2 启动 historyserver
完成上面配置,重启 Hadoop 集群后,执行命令 jps,只会看到如下的进程:
1
2
3
4
5
6
57042 DataNode
57299 SecondaryNameNode
57722 NodeManager
56826 NameNode
57519 ResourceManager
57983 Jps
此时,需要执行如下命令,才能启动 Yarn 的 history 服务进程。
1
mr-jobhistory-daemon.sh start historyserver
再次执行命令 jps,可以看到会新启动 JobHistoryServer 进程,表明 master 机器中启动 history server 成功。之后,在集群中的其它机器中全部执行上述启动命令。
1
2
3
4
5
6
7
57042 DataNode
61075 Jps
57299 SecondaryNameNode
60804 JobHistoryServer
57722 NodeManager
56826 NameNode
57519 ResourceManager
2.3 在 Web UI 中查看日志信息
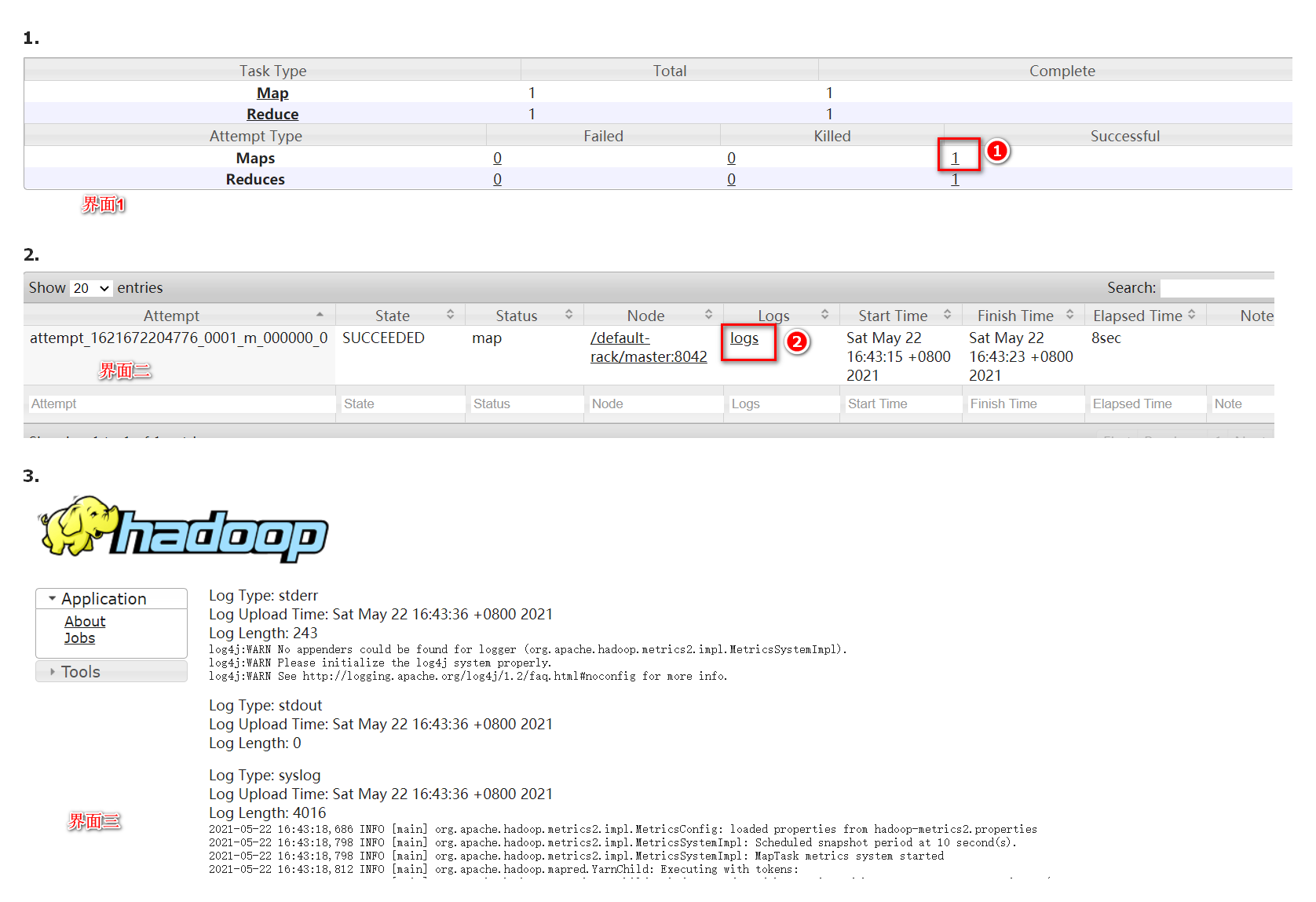
当完成上面的所有配置之后,再点击 http://master机器ip:8088/ 界面中的 History 按钮后,会进入下图的界面 1 中,然后点击标号 1 的位置,会进入界面 2。之后,在界面 2 中点击标号 2 的位置,进入界面 3 ,即日志信息界面。