本文主要是记录阅读《Spark Cluster Computing with Working Sets》的一些笔记。《Spark Cluster Computing with Working Sets》这篇论文首次提出了 Spark ,作者在论文中介绍了 Spark 的编程模型并且通过三个案例来介绍 Spark 的特点。
1. 背景介绍
MapReduce 存在如下两个方面的缺陷:
- 迭代任务:每次迭代的过程都可以看作是一个 MapReduce 作业,而每个作业都要从磁盘中加载数据,从而导致严重的性能损失
- 交互式分析:在使用如 Pig、Hive 进行 SQL 查询时, Hadoop 每次查询都会有严重的延迟(几十秒),因为 Hadoop 将查询作为一个独立的 MapReduce 作业,从磁盘中读取数据
在该论文中,提出一种新的集群计算框架,称之为:Spark,该框架和 MapReduce 一样具有弹性、容错性 。在 Spark 中一个重要的概念是 RDD(resilient distributed dataset,弹性分布式数据集),它表示分布在一组机器上的只读对象集合,如果其中一个分区丢失了依然可以重建。
2 编程模型
2.1 Resilient Distributed Datasets(RDDs)
如果 RDD 中的节点损坏了,RDD 依然可以被重建。这是因为 RDD 的句柄包含了足够的信息计算出 RDD 在可靠存储数据中存储的开始位置。
在 Spark 中,每个 RDD 都是用一个 Scala 对象表示,Spark 允许编程人员以如下四种方式构建 RDD 。
- 从一个共享文件系统中构建(如 HDFS)
- 通过在一个驱动程序(driver program) 中 “parallelizing ”一个 Scala 集合,也就是将它分为多个片,然后发送到多个节点上
- 通过 “transforming” 一个已经存在的 RDD
- 通过改变一个已存在的 RDD 的 “persistence” 状态。默认情况下,RDDs 是懒加载和短暂的。也就是只有当它们在一个并行操作中被使用了,它们才会被实例化,当它们使用完了之后就会从内存中丢弃。用户可以通过如下两个操作来更改 RDD 的 persistence 状态:
- “cache” 操作使数据集懒加载,但是在第一次计算之后就会保存到内存中,因为它可能会被重用
- “save” 操作计算数据集并将其保存到分布式文件系统中,如 HDFS 。
2.2 Parallel Operation
RDDs 上可以执行如下的一些并行操作:
- reduce:通过 associate 函数整合数据集中的元素
- collect:将数据集中所有的元素发送给驱动程序
- foreach:通过用户提供的函数来遍历数据集中的元素
注意:在该篇论文发表时,Spark 不支持像 MapReduce 中分组分组 reduce 操作。
2.3 Shared Variables
Spark 允许编程人员创建两种受限的共享变量,这两种共享变量分别如下:
- Broadcast variables(广播变量):如果一个比较大的只读数据块在多个并行操作中使用,只为每个工作节点发送一次数据要比为每个闭包都发送一次好
- Accumulators:这些变量只能进行 “add” 操作,并且只能被驱动读。累加器可以被定义成任意类型,只要该类型具有 “add” 操作、能赋值 0 即可
3. 案例
3.1 Text Search
在一个存储在 HDFS 的大日志文件中统计出包含错误的行,它可以通过一个文件数据集对象(file dataset object)来实现,演示代码如下:
1
2
3
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val ones = errs.map(_ => 1) val count = ones.reduce(_+_)
创建一个叫 “file” 的分布式数据集,它将 HDFS 文件表示成一个行集合。通过转换这个数据集创建一个包含错误的行集合 errs,然后将每行都映射成值为 1 的 map ,最后通过 reduce 进行累加。
如果我们想重要 errs 数据集,我们可以通过如下代码创建一个缓存的 RDD:
1
val cachedErrs = errs.cache()
我们可以像平常一样调用 cachedErrs (或从其派生的数据集)的并行操作,当 cachedErrs 第一次被计算出来后,节点就会将它们缓存在内存中,这样在接下来的操作中会大大地加快速度。
3.2 Logistic Regression
逻辑回归是一个反复迭代的分类算法,该算法试图找到一个超参数 w 来更好地区分两种类别。在内存中缓存数据对这种迭代的操作非常有帮助,接下来我们会用它来展示 Spark 中的一些特性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Read points from a text file and cache them
val points = spark.textFile(...)
.map(parsePoint).cache()
// Initialize w to random D-dimensional vector
var w = Vector.random(D)
// Run multiple iterations to update w
for (i <- 1 to ITERATIONS) {
val grad = spark.accumulator(new Vector(D))
for (p <- points) { // Runs in parallel
val s = (1/(1+exp(-p.y*(w dot p.x)))-1)*p.y
grad += s * p.x
}
w -= grad.value
}
首先,我们创建了一个叫 points 的 RDD,通过 for 循环来处理它,for 关键字是 Scala 里面的语法糖,它实际上是通过调用集合的 foreach 方法,将循环体作为一个闭包。
此外,为了梯度求和,我们使用了一个叫 gradient 的累加器变量,并且使用了一个重载的 += 操作符进行循环累加。累加器和 for 语法使得 Spark 程序看起来更像一个命令串行程序。
3.3 Alternating Least Squares
Alternating Least Squares(ALS)算法是用来处理协同过滤的问题,比如说基于用户的电影评分历史数据来预测用户对那些他们没有看过的电影的评分。
ALS 的基本过程:假设我们想要预测用户 u 对电影 m 的评分,并且我们有一个已经填充了部分的矩阵 R, 这个矩阵包含了一些已知的用户对电影的评分。ALS 将 R 作为两个矩阵 M 、U 的积,M 和 U 矩阵分别用 m × k 和 k × u 来表示;这表示每个用户和每部电影有 k 维特征向量来描述它们的特点,用户对电影的评分即为用户特征向量和电影特征向量的积。ALS 通过已知的评分来获得 M 和 U 矩阵,然后通过计算 M × U 来预测未知的评分。该算法主要通过如下的迭代过程来实现:
- 随机初始化矩阵 M
- 通过给定的 M’ 来优化 U,使得 R 上的误差最小
- 通过 U 来优化 M ,使得 R 上的误差最小
- 重复步骤 2 和步骤 3 直到收敛
ALS 可以在步骤 2 和步骤 3 中在每个节点上更新不同的用户/电影,从而使得该算法并行化。然而,步骤 2 和步骤 3 都在使用矩阵 R,因此将 R 作为一个广播变量是非常有利的,因为不需要在每步中都为每个节点重新发送数据。代码的代码如下:
1
2
3
4
5
6
7
8
9
val Rb = spark.broadcast(R)
for (i <- 1 to ITERATIONS) {
U = spark.parallelize(0 until u)
.map(j => updateUser(j, Rb, M))
.collect()
M = spark.parallelize(0 until m)
.map(j => updateUser(j, Rb, U))
.collect()
}
注意:我们并行一个 0 到 u 的集合,并且 collect 这个集合来更新每个数组 U。
4. 实现
Spark 是建立在 Mesos 之上,Mesos 是一个 集群操作系统,它允许多个并行程序以一种细粒度的方式来共享一个集群,同时为应用程序提供在集群上启动任务的 API。这使得 Spark 能够与现有的一些集群计算框架一起工作,如 Hadoop、MPI 的 Mesos 端口。
Spark 的核心是弹性分布数据集(RDD)的实现。比如说,假设我们定义了一个叫 cachedErrs 的缓存数据集,它用来表示一个日志文件中的错误信息,我们通过使用 map 和 reduce 操作来统计元素的个数,代码如 3.1 中所示:
1
2
3
4
5
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)
这些数据集将作为对象链来存储,对象链中含有每个 RDD 的起源(lineage)信息,如下图所示。每个数据集对象含有指向父节点的指针以及父节点如何转换的信息。
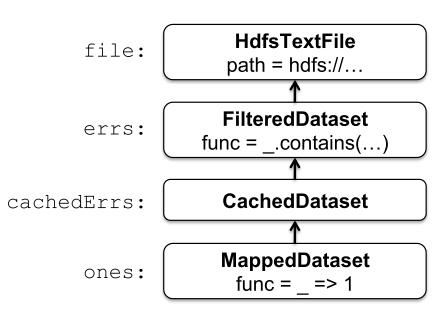
在内部,每个 RDD 对象都实现了相同的简单接口,这些接口包含了如下三个操作:
- getParitions:它返回的分区 id 的列表
- getIterator(partition):在一个分区上进行遍历
- getPreferredLocations(partition):用来实现任务的高度,以实现数据的局部性
不同类型 RDDs 的区别只在于它们实现 RDD 接口的方式。例如:对于一个 HdfsTextFile ,分区是 HDFS 中块的 id ,它们首选的位置是块位置,通过 getIterator 打开流读取块内容。在 MappedDataset ,分区和首选位置与它的父节点是一样,但是 getIterator 是对父节点的元素使用 map 函数。在 CachedDataset 中,getIterator 方法是找到已转换分区在本地缓存的副本,刚开始分区的首选位置与父节点一样,但是当分区缓存在一些节点后就会进行更新,这样以便更好地利用该节点。这种设计使得错误很容易处理,如果一个节点出现错误,它的数据集将从父数据集中重新读取,并最终缓存到其他的节点中。
共享变量:有广播变量、累加器两种共享变量,它们是通过自定义序列化的类来实现的。
- Broadcast Variables:当创建一个广播变量 b ,并为其赋值为 v 时,v 保存在共享文件系统中的一个文件中,b 的序列化格式即为该文件的路径。当 b 在一个工作节点中被使用时,Spark 首先会检查 v 是否是本地缓存,如果它不是则从文件系统中读取它。最初是使用 HDFS 来创建广播变量,后来开发出一个更高效的流广播系统
- Accumulators:通过使用不同的 “serialization trick” 来实现,每个累加器在创建时都会有独一无二的 id。当累加器被保存时,它的序列化包含了它的 id 以及零值。
解释器集成:在 Spark 中集成了 Scala 的解释器,但是对 Scala 的解释器做了如下两点的改变。
- 将解释器定义的类输出到共享文件系统中,工作节点可以通过自定义的类加载器加载它们
- 改变 Scala 生成的代码,让每行代码对应的单例对象直接引用前面行的单例对象,而不是通过 getInstance 方法获取前面的行单例对象。这样就可以使得:无论行单例对象什么时候被序列化发送给工作节点,都可以捕捉到其引用的单例对象的当前状态。
注意: Scala 解释器会将用户输入的每一行都编译成一个类,这个类包含了一个单例对象,该单例对象包含了该行的函数及变量并且会在构造方法中运行该行对应的代码。比如说,用户在第一行中输入了 var x = 5 ,然后在下面又输入一行 println(x) ,那么 Scala 编译器会就会为第一行编译一个类(假设命名为 Line1),在第二行中实际上就是 print(Line1.getInstance().x)。